バンドギャップ予測アプリ作成中
2026年11月16日(日)に、バンドギャップ予測アプリの作成を試みた。
↓WSLを使用
↓sudo pip install mp-api pandas
↓bandgap_dataset_from_MP.pyという名でスクリプトを作成
スクリプトは下記
“””
Materials Project からバンドギャップ付きデータを取得して
bandgap_dataset_from_MP.csv を作るスクリプト
“””
from mp_api.client import MPRester
import pandas as pd
======================================================
★ここに「新しい APIキー」を貼る
======================================================
API_KEY = “YOUR_API_KEY_HERE” # <– ダブルクォート必須 # どれくらいデータを取るか N_DOCS = 1500 # 最初は1500件くらいがバランス良い def main(): fields = [ “material_id”, “formula_pretty”, “band_gap”, “density”, “volume”, “nsites”, “symmetry”, ] rows = [] with MPRester(API_KEY) as mpr: docs = mpr.materials.summary.search( band_gap=(0.01, None), # 半導体に絞る fields=fields, chunk_size=500, ) for i, doc in enumerate(docs): if i >= N_DOCS:
break
crystal_system = getattr(doc.symmetry, “crystal_system”, None)
spacegroup_symbol = getattr(doc.symmetry, “symbol”, None)
rows.append(
{
“material_id”: str(doc.material_id),
“formula”: doc.formula_pretty,
“band_gap”: doc.band_gap,
“density”: doc.density,
“volume”: doc.volume,
“nsites”: doc.nsites,
“crystal_system”: crystal_system,
“spacegroup_symbol”: spacegroup_symbol,
}
)
df = pd.DataFrame(rows)
df = df.dropna(subset=[“band_gap”, “density”, “volume”])
print(“Fetched rows:”, len(df))
out_name = “bandgap_dataset_from_MP.csv”
df.to_csv(out_name, index=False)
print(f”Saved: {out_name}”)
if name == “main“:
main()
↓APIキーをスクリプトに挿入し、デスクトップに保存
↓Ubuntuの~/ishik/materials-ai/に配置
*メモ
・フォルダーをつくるときは、mkdir
・ファイルをつくるときは、touch
・編集は nano
・移動させるときは、mv 移動したいもの 移動先/
・上書きを確認したい場合は -i を付ける:mv -i a.txt docs/
・コピーは、cp file.txt コピー先/
↓python環境作りのやり直し
sudo apt update
sudo apt install -y python3 python3-venv python3-pip
↓プロジェクト用フォルダの作成
↓venv(専用Python環境)を作る
python3 -m venv .venv
↓venv(専用Python環境)をアクティベート
source .venv/bin/activate
↓pipとpandasをインストール
pip install –upgrade pip
pip install mp-api pandas
↓仮想環境で、python bandgap_dataset_from_MP.py実行。
Q:なんで仮想環境をつくったか?
A:「WSL のシステムPythonは “勝手に pip install を禁止している” から、
あなた自身の環境(venv)を作らないとライブラリを入れられない。」ためです。
↓KNIMEを使うために、取得したCSVをウィンドウズから読める場所におく
単純に、windowsのデスクトップにドラグした。
↓KNIMEのHPからKNIMEをダウンロードし、インストールした。
↓起動後にやったこと
KNIME 起動
「File → Preferences」
「KNIME → Memory Policy」
16Gのメモリなので、8000MBとした。
理由は、KNIME が大きいCSV(今回の1500行 × 7列なら余裕)を扱うときに
高速 + エラーになりにくくするため。
KNIME での操作:
KNIME を起動
左上「New Workflow」から新しいワークフローを作成
例:Bandgap_MP_Model
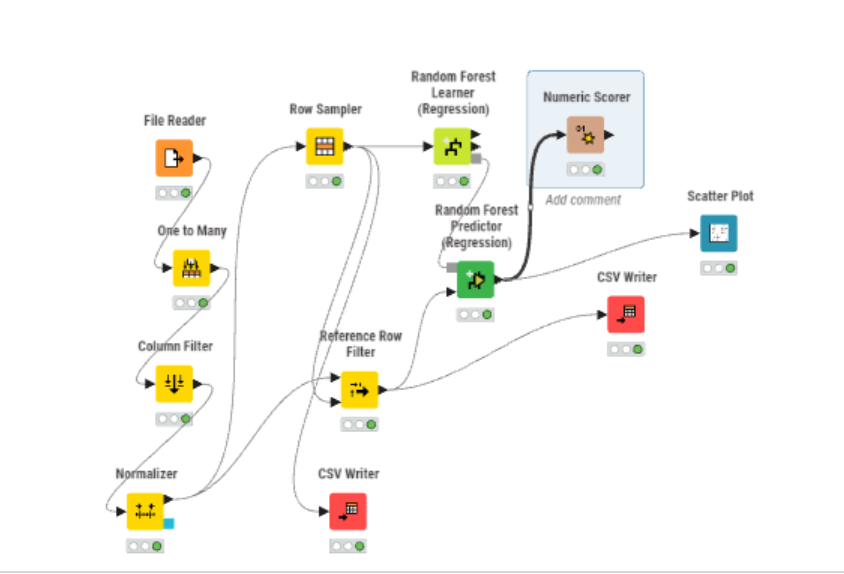
「File Reader」をワークフロ―画面にドラッグ
ダブルクリックして設定画面を開く
bandgap_dataset_from_MP.csv を選ぶ
「Apply & Close」して実行(右クリック → Execute)
One to Many をワークフローにドラッグ
File Reader → One to Many を線で接続
One to Many を ダブルクリック(設定画面を開く)
設定:
“Columns” で
→ crystal_system を選択
Apply & Execute
メモ:今回の特徴量は以下。
density
volume
nsites
crystal_system(ダミー化済み)
次回以降にやること
🔥 追加できる特徴量の例(matminer)
元素組成の平均イオン化エネルギー
カチオン・アニオン半径
元素電気陰性度の統計量
Mendeleev Number
Valence orbital 平均
Ewald energy
Composition Entrpy …などを Python で作り、
CSV に 20〜100列の特徴量 を追加し、予測精度をあげる。
Column Filter ノードを接続。
「Include(残す列)」
band_gap
density
volume
nsites
crystal_system_*(One to Many で増えた0/1列全部)
「Exclude(消す列)」
material_id
formula
spacegroup_symbol
→ Apply and Execute
Column Filter → Normalizer を接続。
Normalizer 設定:
Include:
density
volume
nsites
crystal_system_*(全部)
Exclude:
band_gap(目的変数なので正規化不要)
Normalize method:
Z-Score (mean=0, variance=1) でOK
→ Apply and Execute
Row Sampleを接続
*ここでChatGPT間違いつづける。
グルグルしたが、アイキャッチ画像のワークフローになった。
以下で混乱。
① Prediction (band_gap)
これは 最終的な予測値
→ ランダムフォレストが算出した band_gap の「予測結果」。
入力した材料の band_gap を 2.31 eV と予測した
みたいな最終アウトプット。
② Prediction (band_gap) (Prediction Variance)
これは 予測のバラつき(不確かさ) の指標。
KNIMEのモデルの出力
CSV writerで以下のファイルを出力した。
C:\Users\ishik\test_data.csv
C:\Users\ishik\train_data.csv
その後、WSLのフォルダーに移動させた。
pythonで軽量データの作成を行った。
仮想環境で、pip install pandas scikit-learn